
One of the reasons I like working at Redox as a solutions engineer is that I get to help our prospective and current customers solve hard problems with creative solutions. Something I’ve seen firsthand over the last couple of years is that there is a big difference between what you’d think should be possible (or what will be possible) and what actually is possible. In healthcare, there’s no shortage of such gaps. This is what keeps us busy here at Redox.
Over the next several weeks I will release a series of blogs highlighting the way Redox is helping our customers overcome these gaps to uncover the possible. We don’t just help our customers build “future-proof” solutions at Redox. Our solutions effectively launch them into the future, to a world where data flows seamlessly, workflows are optimized, and patient experiences are delightful. Up first: Using bulk FHIR.
What is bulk FHIR?
Like many aspects of HL7® Fast Healthcare Interoperability Resources (FHIR®), there has been a lot of hype about the potential of using bulk FHIR to get large amounts of data out of EHRs. Redox has many customers who are interested in this for things like cohort analysis, AI model training, population health, and more.
Individual FHIR resource APIs are useful for retrieving a specific type of data for a specific patient in one API call — for example, a single patient’s problem list or medication list. But they aren’t optimized for retrieving the problem list and medication list for thousands of patients in one go. That’s where bulk FHIR comes in. Instead of making many API calls to get the data you need, you can make one API call that kicks off a process culminating in an output containing all the EHR data you requested. If you’re a software vendor who’s ever wondered, “Why can’t I just run a big ol’ SQL query against the EHR database?” bulk FHIR is a significant step closer to that.
The current state of bulk FHIR via EHRs
Today, few EHRs robustly support bulk FHIR, and those that do have differing depths of support for it, making bulk FHIR an unrealistic pathway for implementing any of the use cases listed above across different systems. Even Epic, which has adopted FHIR more extensively than most EHR vendors, contends that “Data exports for groups of over one thousand patients” is a poor use case for bulk FHIR. I’m not an expert, but doing any sort of meaningful population health work would be difficult when you’re getting data for fewer than a thousand patients.
So, what’s a company in need of a lot of patient data to do? It’s reasonable to assume that bulk FHIR’s real-world usefulness will improve in the coming years, especially given the final rule from ONC in early January that defines additional requirements for FHIR adoption…by 2026. But what if you need to solve these problems now?
Achieving bulk FHIR, now
As we always strive to do, Redox is helping our customers get the job done despite current limitations in EHR vendor support for bulk FHIR. Our goal at Redox is to design solutions that are as agnostic of differences in EHR capabilities as possible, so even if bulk FHIR works great with a couple of EHR vendors, that’s not good enough for our customers.
Using the Redox platform, our API engineers have built a mechanism that allows for the retrieval of large FHIR datasets in the absence of robust EHR support for bulk FHIR. Further, Redox allows our customers to post these massive datasets to Google, AWS, and Microsoft Azure data stores via our adapters for each of these cloud vendors.
Typically, this Redox capability involves a trigger event (such as an HL7 message or a patient roster upload) which initiates a customizable scope of FHIR resource queries to the EHR’s FHIR endpoints, which we bundle together for delivery to a destination system. That’s a lot of buzzwords, so maybe just take a look at the visual below:
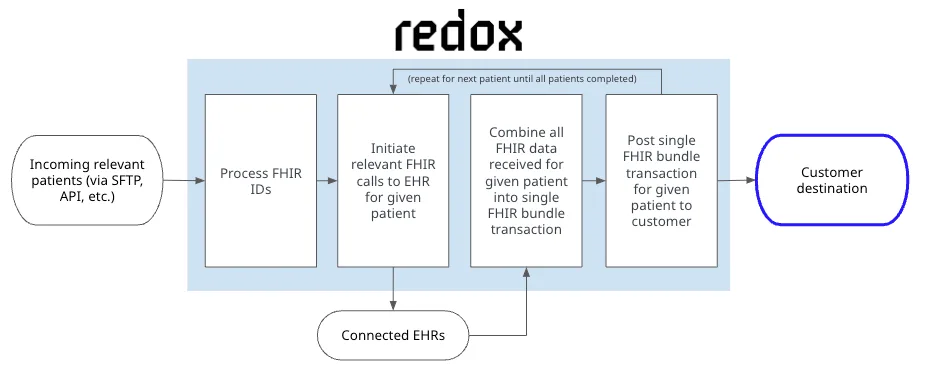
The way we are approaching bulk access to FHIR data is novel (and pretty cool, I think). Here are a few highlights:
- Flexible: While the current implementations of bulk FHIR allow for some flexibility with the scope of data that’s requested, we can use any of the parameters of a FHIR resource endpoint to include or exclude data. We can also configure our system to deliver the outputted data to our customers in different ways, such as via an API endpoint or SFTP transfer (hey, it wouldn’t be healthcare if we weren’t invoking an old-school standard somewhere in this blog post).
- Scalable: Instead of kicking off a bulk FHIR query and then having what happens next be somewhat of a black box until it’s done, we’re able to deliver data to our customers as it’s available. We can also ramp up to retrieve data for as many patients as is necessary.
- Performant: As you might expect, a healthcare organization’s tolerance for being hit with a large number of FHIR queries will vary. We can adjust our query throughput by organization and also optimize to account for things such as off-peak hours, even when live data feeds such as HL7 v2 are the initiating events for our queries.
I just know one of my college professors is looking at this and remembering that I skipped the lectures about efficiency in my computer science classes. But, I promise I did my homework. Using our approach, we’ve helped one of our digital health technology customers to populate a disease registry with data from hundreds of thousands of patients across many different EHR instances and healthcare organizations.
This customer saw a reduction in data retrieval times from being measured in weeks to hours, resulting in their ability to deliver more timely data to their healthcare organization customers, equipping them to make informed decisions about patient care — all while reducing the time and effort required by the healthcare organization IT teams to get the data out of their EHRs.
We’re excited to continue to refine this feature as more of our customers adopt it, and adapt it as EHR bulk FHIR capabilities advance. I’d love your feedback on this post. You can send your questions and comments to [email protected]. I’ll be back soon with Part II of this series, which will focus on how we bridge the gaps between differences in the capabilities of HL7 v2 and FHIR APIs.
HL7® is a registered trademark of Health Level Seven International. The use of this trademark does not constitute an endorsement by HL7.
FHIR® is a registered trademark of Health Level Seven (HL7) and is used with the permission of HL7. Use of this trademark does not constitute an endorsement of products/services by HL7®.