
Every transformational technology goes through two phases. First the technology. Then the infrastructure that makes it actually work at scale.
The internet existed before the browser. Smartphones existed before the App Store. Cloud computing existed before AWS abstracted away the servers. In each case, the infrastructure moment came second. And that’s the moment when adoption exploded – because the technology became usable. It eliminated the need for humans to manually fill the gap.
AI for healthcare data is squarely in phase one right now. The AI models are capable. Team members spend hours and days getting a cohort of the data ready for the AI pilot. The pilot results are promising, demonstrating that the AI works as intended. However, almost universally, the scale-up stalls on the same thing: the data “infrastructure” underneath the AI wasn’t built for this job. Without the tedious manual prep, the AI doesn’t work as well.
Most data infrastructure today was built to solve a movement problem. Get the data. Move the data. Done. AI doesn’t have a movement problem. It has a readiness problem. And that requires a different foundation.
AI for healthcare data is ready for its infrastructure moment
Use cases for AI in healthcare data in controlled settings are proven. Organizations have run the pilots and seen what’s possible for clinical summarization, prior authorization automation, risk prediction, care gap identification. We’ve all seen the articles and LinkedIn posts. None of these are speculative anymore.
Yet, we aren’t seeing the same results at scale. Why? The data isn’t ready.
Not because of a lack of effort or talent. In fact, I’d bet that in your organization, there is an incredibly talented team of integration engineers who know your systems better than anyone. They know where the data lives, how it’s structured, what the edge cases are, which fields are populated and which are ghost towns. They, along with your data, are trapped in silos, 1:1 custom pipelines, and legacy data formats.
For many decades of HL7 mandates and FHIR APIs and integration engineering, the finish line was moving data from point A to point B , in a format that was technically valid. This was (and still is!) a hard problem to solve, and the interop systems were designed to optimize for that job.
The work of shaping data for action has historically required days of fragmented effort: mapping fields, understanding formats, writing and rewriting configs, testing, validating, starting over. Two or more days of work, often spread across a week, for a task that should take an afternoon.
However, the finish line has changed. Data movement is not the same as data being ready for AI. And readiness is what AI actually requires. We are ready for our infrastructure moment.
Data infrastructure jobs to be done: connectivity, readiness, and orchestration
The infrastructure layer that ensures healthcare data is ready for AI has three jobs.
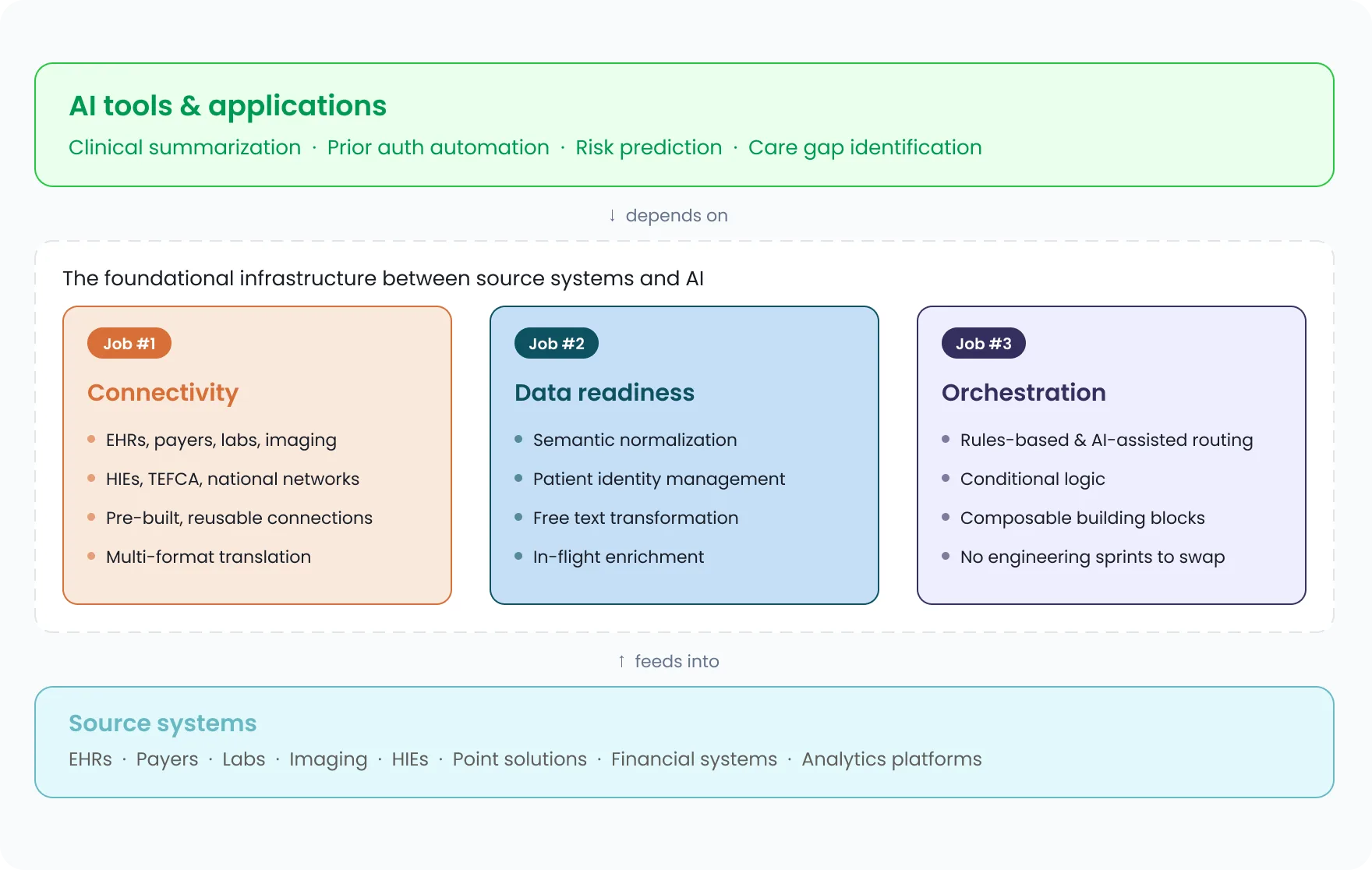
Image: Data infrastructure layer and its three jobs
Job #1: Connectivity
Data has to move, in the right formats, from the right sources, across an ecosystem that keeps getting larger and more complex.
Why it’s hard: EHRs alone come in over a hundred configurations, and as my colleague Sasi Mukkamala, CTO at Redox, wrote recently, if you’ve seen one instance of an EHR at one provider organization, you’ve seen one instance of that EHR. Add point solutions, payer systems, labs, imaging, HIEs, national networks like TEFCA, CRMs, analytics platforms, and financial systems, and the complexity quickly becomes overwhelming. And we didn’t even mention what it takes to knock down internal data silos.
Winning approach: Connectivity infrastructure should understand all the data formats and standards and translate fluently across them. It should have reusable, pre-built connections across payers, EHRs, labs, HIEs, and national networks like TEFCA. This way, you’re not rebuilding from scratch each time, you’re just customizing the last ten to twenty percent. The format, the standard, the translation: that’s the infrastructure’s job, not yours.
Job #2: Data Readiness
Getting data into the right system in a harmonized format that’s technically valid AND clinically useful.
Why it’s hard: The definition of ‘useful’ is in the eye of the user … and each company has a custom view of what ‘useful’ data may look like. In one example, it means including all potentially normalized codesets across a varied provider base. In another example, it means ensuring the organization’s tagged patient identifier is applied.
Winning approach: Defining what ‘useful’ means for your organization, and having infrastructure that operationalizes that definition at scale. Not a universal standard imposed from outside. Your logic, your thresholds, your view of a complete record, applied automatically as data moves.
Job #3: Orchestration
This is more than simple routing, it is moving data with intent. Orchestration is what turns a data exchange into an actual workflow, one the AI downstream can depend on.
Why it’s hard: Real-time routing to multiple destinations, in multiple formats, based on conditional logic, is hard enough to build once. The harder problem is maintaining it. Upstream inputs change. New destinations are added. Formats evolve. Every change is a potential break, and someone on your team owns that break at 2am.
Winning approach: A scalable, visual interface with composable, swappable building blocks that makes rules-based routing, intent-based routing, conditional logic, and more as easy as putting together a Lego set.
Together, these three capabilities form what I think of as a composability layer: the infrastructure between your source systems and your AI applications. It does the preparation work that needs to be done before AI can do its job. Without it, even the most capable model is working on inputs it can’t fully trust.
The AI is ready. Make sure your data is ready too.
The models are ready. The question worth sitting with is whether your data infrastructure is ready to unblock them.
That means all three jobs working together: connectivity that meets source systems where they are, data readiness logic that reflects your definition of useful, and orchestration that routes and acts with real intent (without requiring your team to manually hold it together). Each job matters on its own. But the real leverage is in having them work as one coherent foundation rather than three separate problems your engineers are solving in parallel.
AI for healthcare data is here. The only question is whether your data infrastructure is ready for it.
This post was written by Rachel Witalec, Chief Product Officer at Redox. Earlier posts in this series explored the inter vs. intra distinction in AI-ready data infrastructure and why vibe-coded AI fails in production (and what it actually takes to close the gap between demo and deployment).