
Explore our library of composable workflows built for common use cases across provider organizations, payers, and health tech. Built from modular building blocks, these end-to-end data flows are designed to be flexible, allowing you to rearrange and customize components to fit your needs. Because Redox extends far beyond traditional EHR connectivity, these workflows can orchestrate data, documents, business logic, and operational actions across the broader healthcare ecosystem.
Clinical record enrichment & summarization via AI/LLM
Who it’s for: Provider organizations
Automatically generate patient summaries by merging real-time EHR data with external HIE context, providing AI/LLMs with the full clinical picture.
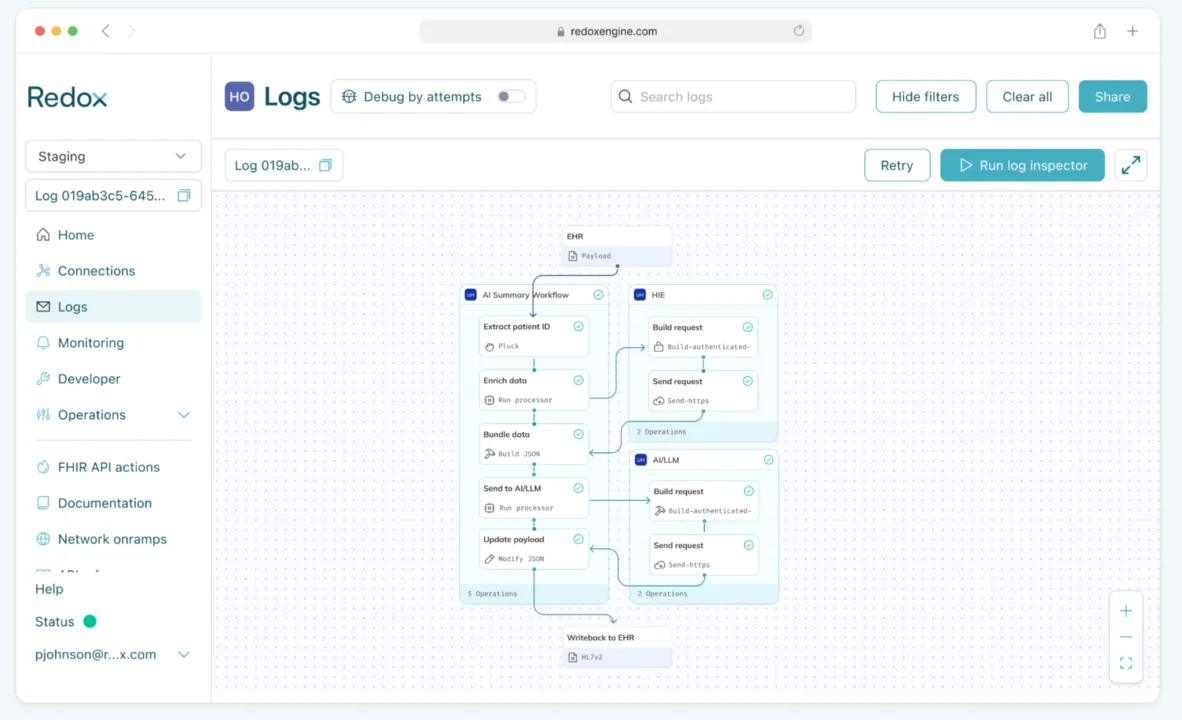
Building blocks used:
- Ingest & convert: Redox ingests real-time EHR data and converts it to FHIR.
- Extract: Patient identifier is extracted from FHIR Event Bundle.
- Enrich: The processor fetches additional patient context from a Health Information Exchange (HIE).
- Bundle: All data is bundled into a single payload.
- Send to AI: The enriched data bundle is sent to the customer’s LLM for summarization.
- Writeback: The AI-generated patient summary is written back to the EHR as an HL7v2 message.
Document routing
Who it’s for: Provider organizations
Triage static PDFs using AI to classify the document type (ex: referrals vs. refills) and instantly route them to the correct downstream destination.
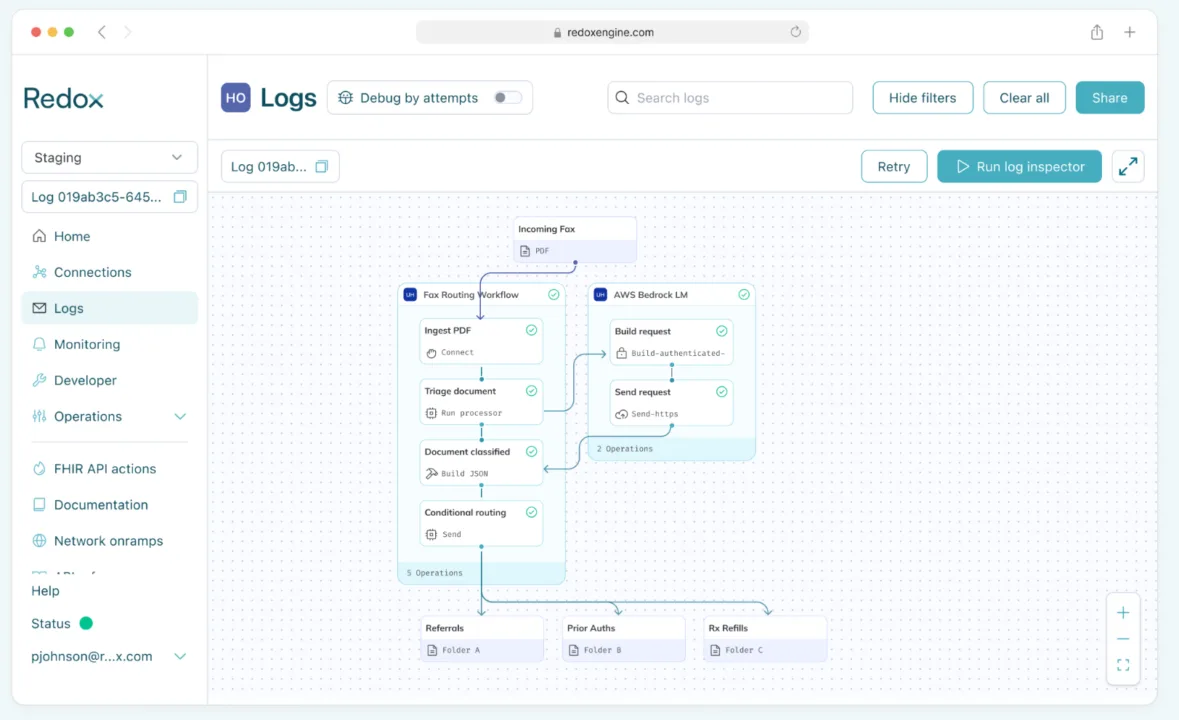
This example is actually a live workflow that Redox built for a large health system. Results include: 59% reduction in expected FTE headcount for manual sorting, 50% reduction in duplicate refill requests, and less than 4 weeks from initial development to full production. Read more here or check out our case study with AWS.
Building blocks used:
- Ingest: Redox connects directly to the health system’s digital fax server (ex: RightFax) to ingest incoming PDFs.
- AI triage (Bedrock LM): The PDF is sent to an LLM (such as AWS Bedrock) to analyze the content and classify it into predefined categories: Referrals, Prior Authorizations, Rx Refills, or Bulk Docs.
- Conditional routing: Based on the AI’s classification tag, the Orchestrate processor determines the final destination.
- Multi-destination send: The document is auto-delivered to the specific endpoint required for that workstream.
Power real-time cloud analytics and writeback
Who it’s for: Provider organizations, Payers
Stream real-time clinical data into cloud platforms like Databricks or AWS to power advanced analytics for use cases like capacity utilization, readmission risk scoring, urgent care/ED wait time management, referral leakage, and more. Then, close the loop by writing outputs directly back into the EHR.
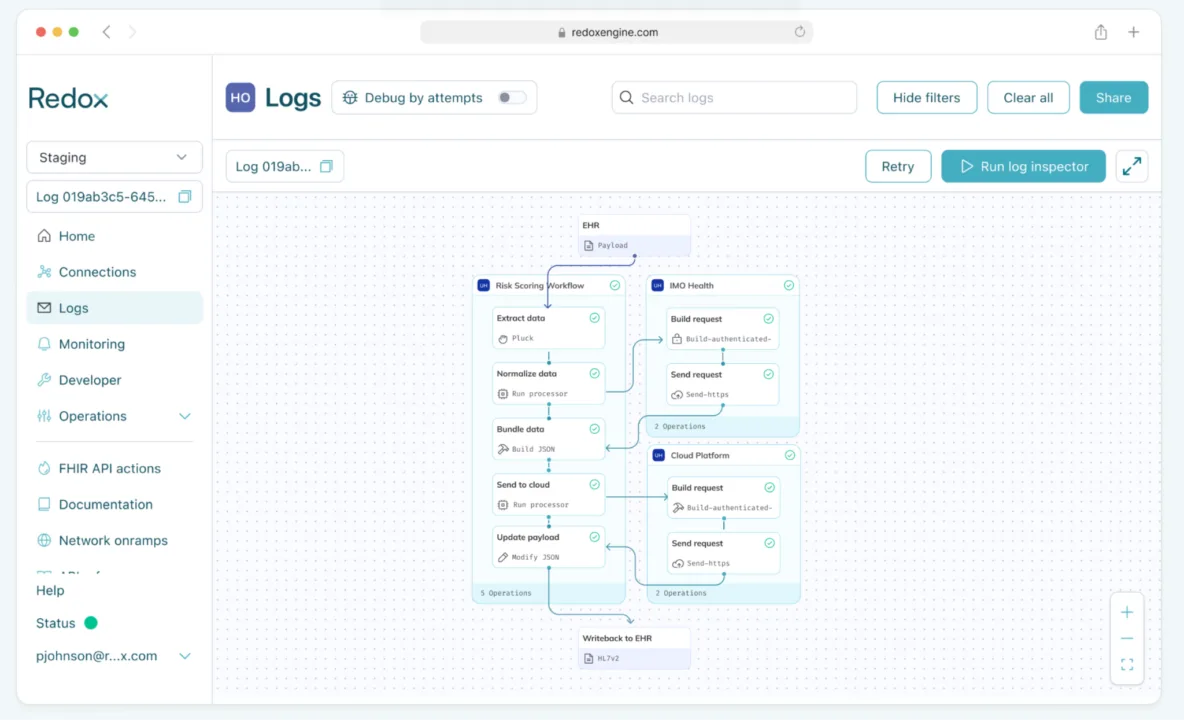
Building blocks used:
- Ingest & convert: Redox ingests real-time clinical data from the EHR and converts to FHIR.
- Normalization via IMO Health: To ensure high-quality analytics, the processor normalizes conditions, medications, procedures, and labs by calling out to IMO Health.
- Send to cloud: The normalized bundle is sent to cloud platforms like Databricks or AWS for analytics.
- Writeback: The resulting output is written back to the EHR as an HL7v2 message.
Automated data enrichment
Who it’s for: Provider organizations, payers, and health tech
Automate context gathering by querying the source system to fetch supplementary data points the moment a trigger occurs.
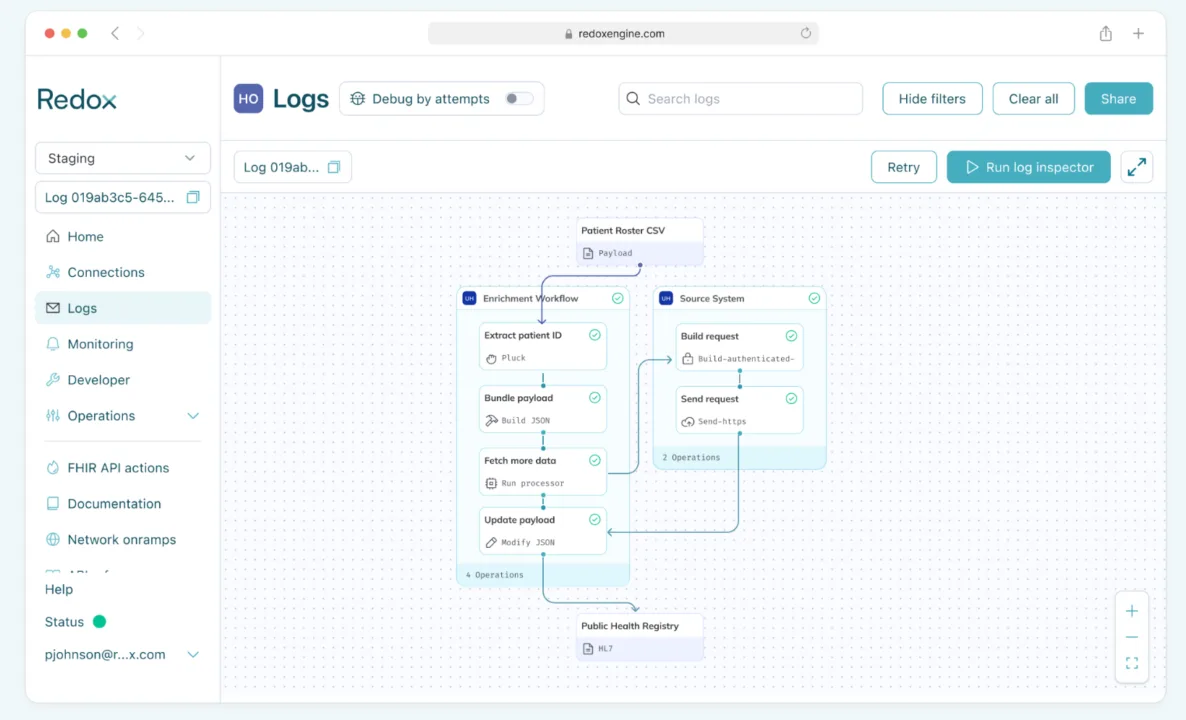
Building blocks used:
- Ingest & convert: Redox ingests real-time EHR data and converts it to FHIR.
- Enrich: The processor fetches additional patient data from the source EHR system or an HIE.
- Bundle: All data is bundled into a single payload.
- Send to destination: As an example, the bundle could then be sent for inclusion in a registry.
Claims & clinical data modernization
Who it’s for: Payers
Ingest and normalize claims and clinical data streams, sending raw data to an archived destination for compliance and analytic-ready FHIR data into the cloud.
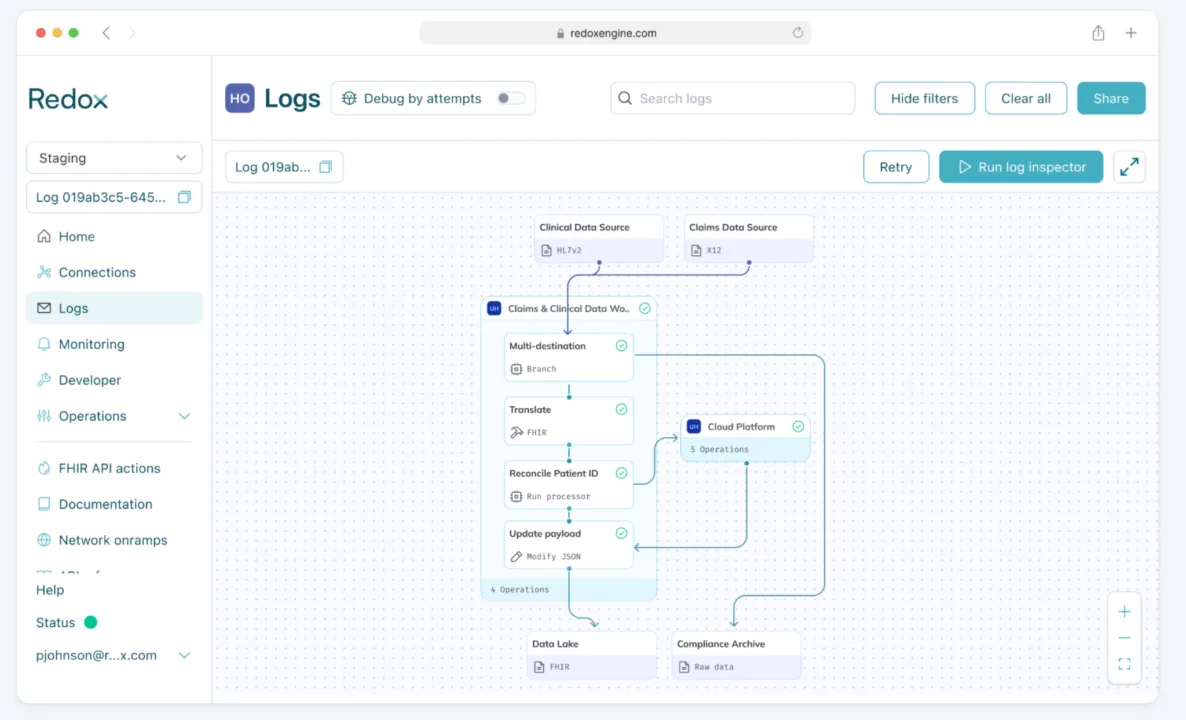
Building blocks used:
- Ingest: Redox ingests clinical data (HL7v2/C-CDA) and claims data (X12) from different sources.
- Multi-destination send: A copy of the raw, untransformed data is routed to an S3 bucket or SFTP for audit and regulatory compliance. The other branch converts data into a unified FHIR R4 format.
- Identity reconciliation: The workflow calls out to a cloud-based MPI (Master Patient Index) or your data lake to match the patient’s identity across both data streams.
- Send to cloud: The reconciled, enriched record is sent to the Cloud Datalake to either create a new patient profile or update an existing one.
Admissions listener
Who it’s for: Provider organizations
“Listen” for specific admission events and automatically prepare a clinical summary for the care team by gathering relevant history before they even open the chart.
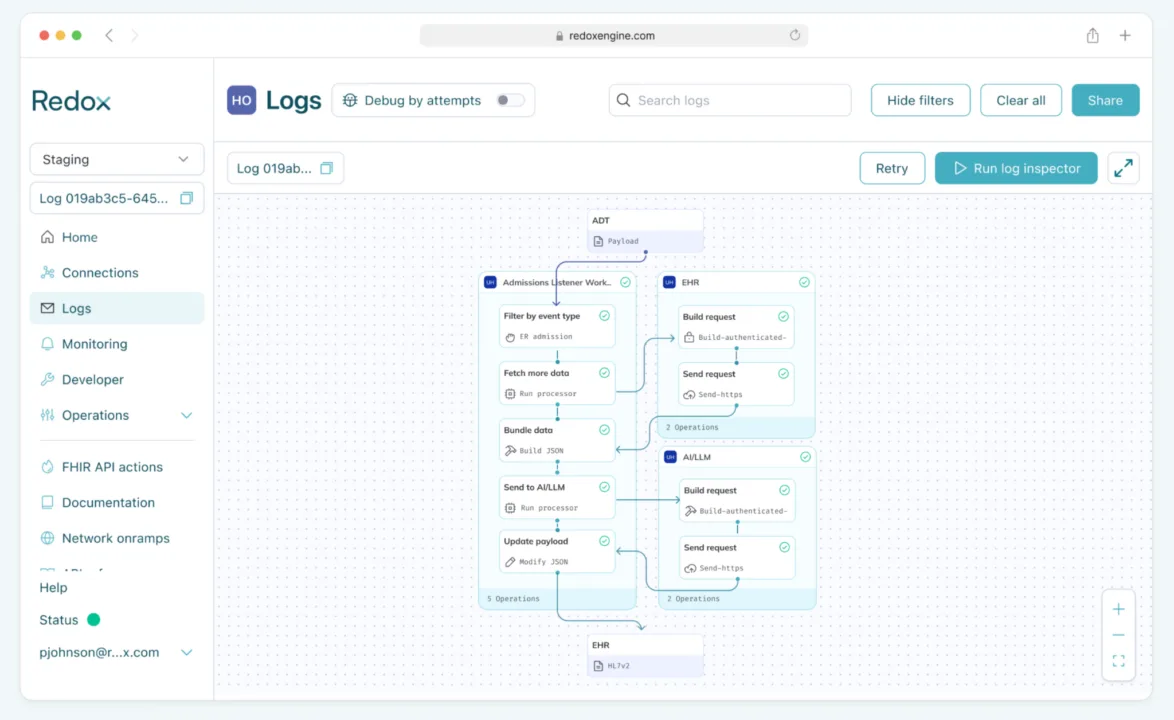
Building blocks used:
- Ingest: listens for real-time HL7v2 ADT (Admission, Discharge, Transfer) messages.
- Filter: The processor inspects the data to determine encounter type (ex: patient admission for chest pain)
- Enrich: For matching events, the workflow triggers an HTTPS GET request to the EHR to pull specific clinical context (ex: the last 24 hours of cardio-related labs and Cardiology consult notes).
- Bundle: The initial ADT data and the newly queried clinical data are merged into a single FHIR payload.
- Summarization (LLM): The bundle is sent to an AI/LLM (internal or external) with a prompt to “Summarize recent cardiac history and acute findings.”
- Writeback: The concise summary is pushed back into the EHR as an HL7v2 message.
Clinical terminology enrichment
Who it’s for: Provider organizations, payers, and health tech
Clean up clinical data before it lands in downstream systems with codeset normalization across major coding systems like ICD-10, SNOMED CT, RxNorm, LOINC, and CPT. Standardizing clinical terminology is critical for downstream analytics, improving RAF score accuracy, reducing data fragmentation, and filling gaps across disparate clinical and claims data sources.
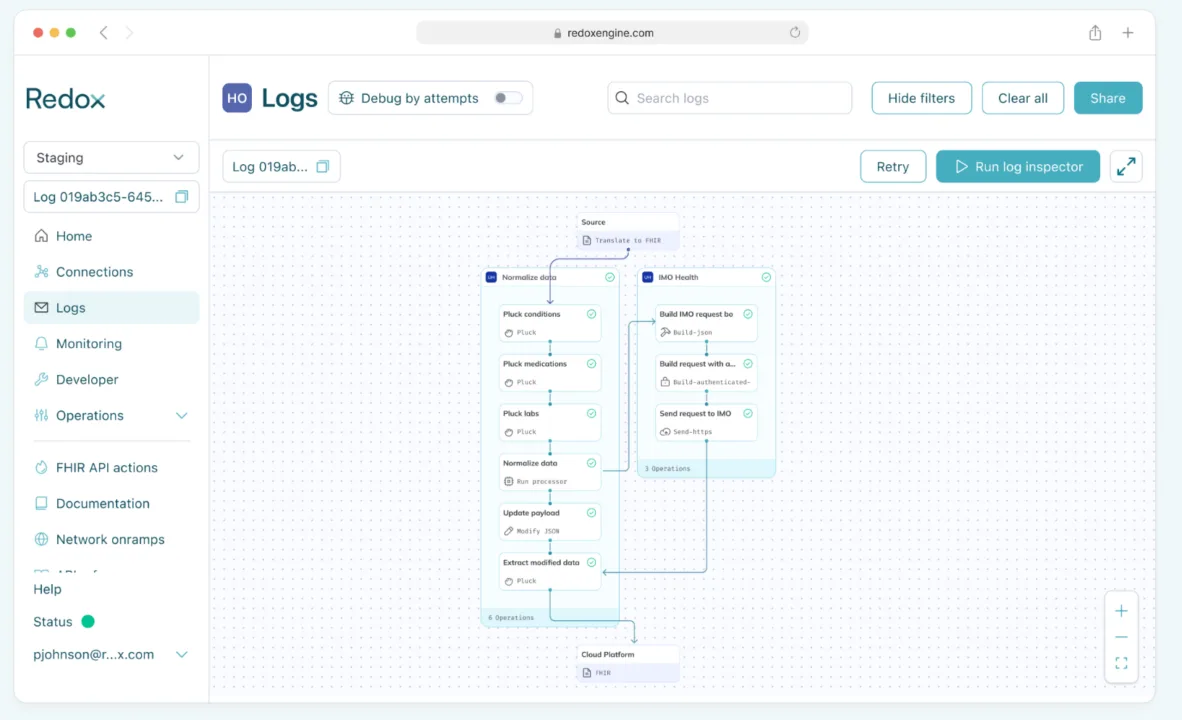
Building blocks used:
- Ingest & convert: Redox ingests real-time clinical data from the EHR and converts to FHIR.
- Pluck data: Specific data domains (like conditions, medications, labs, and procedures) are extracted from the payload for normalization.
- Normalization via IMO Health: Selected data domains are normalized using IMO Health’s terminology engine
- Send to destination: The updated normalized payload is sent to the destination (ex: cloud).
⚡ What to keep in mind:
- “BYO AI” flexibility: The ‘Send to AI’ processor is model-agnostic. Route data to OpenAI, AWS Bedrock, internal models, or secure external endpoints without changing the surrounding orchestration logic
- Modular debugging: Because workflows are composed of discrete processors, failures can be isolated to a specific step without disrupting the rest of the flow. Inspect payloads at each execution point, from raw HL7v2 ingestion through final FHIR transformation, to quickly identify where issues occurred.
- Optimize high-volume workflows: Filter and transform payloads early in the flow to reduce downstream processing overhead, lower cloud costs, and minimize latency for analytics and streaming workloads.
- Precision filtering: Use custom logic to trigger enrichment, LLM summarization, or external queries only for high-priority events, helping reduce unnecessary compute and API usage.
If you’re wondering whether Redox can support a workflow you don’t see here, the answer is probably yes. These examples represent common patterns, but the underlying building blocks are designed to be flexible and composable across a wide range of use cases.
If you have a workflow in mind, there’s a good chance Redox can support it. Reach out to our team to explore what’s possible.